Data contracts as a concept is gaining attention. But, the usual focus in these discussions has been on establishing contracts between source systems and the data platform, the lake/warehouse. These contracts are a critical first step — they set the foundation for what is possible. But getting the data into the platform and shoring up the ingest process is not the end of the story. Data consumers at the other end build all kinds of outputs, often writing custom, one-off scripts to serve common use cases like metrics reporting, metrics root-causing, analysis of experiments and more. I want to discuss how extending the concept of data contracts through to the consumption side of the equation can benefit end consumers and the whole ecosystem.
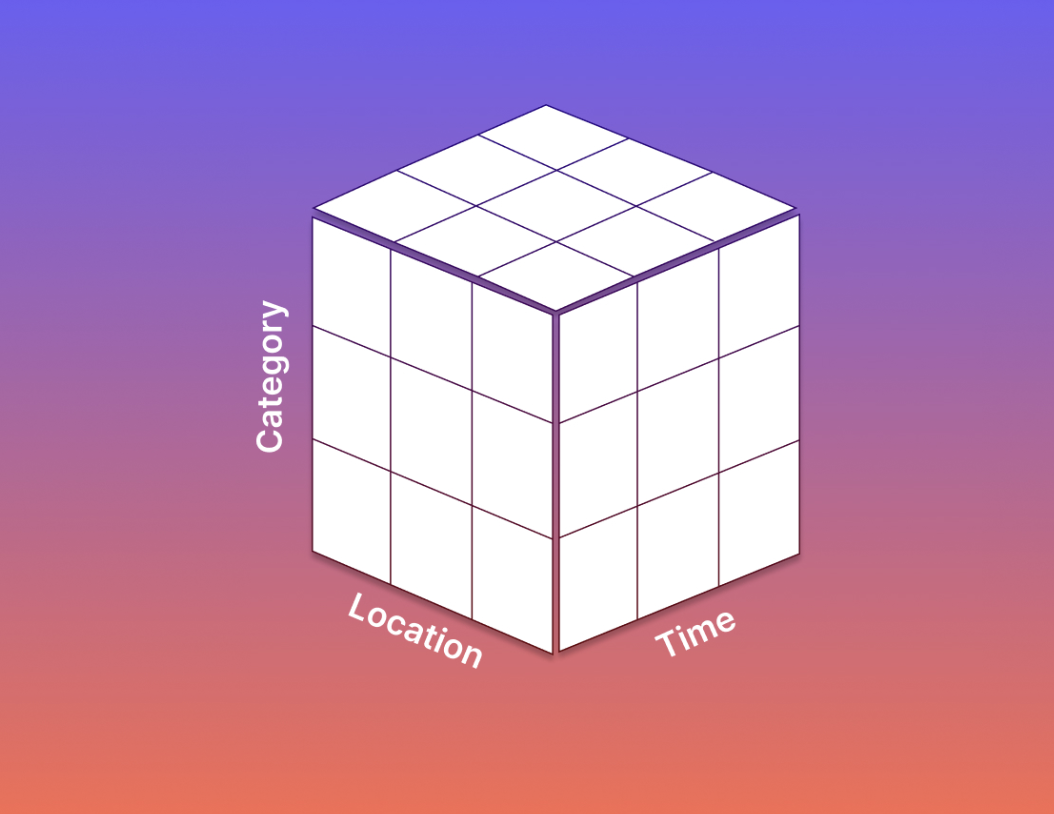
One of the under-exploited attributes of outputs (vs inputs) is that we can empirically observe the common consumption patterns, and utilize that to establish standards and stronger contracts. The biggest use case historically has been reporting on metrics, often on a time series like weekly new and total customers. The early wave of data warehousing gave us the “cube” standard - where we calculate metrics by several dimensional attributes, including time hierarchies. It is such a well-designed concept that every data practitioner uses it whether they are intimately familiar with it or not. But, we have not developed other widely used output standards even as our use cases have gotten more sophisticated. Let’s go through a few such use cases, and see how we could build upon the cube.
1. Experiments: A/B testing is being adopted in many companies, but it is far too common to run experiments without a framework on how to reliably generate outputs, analyze the results and iterate. The classic cube actually provides an excellent starting point, and with meaningful additions, we could conceive of an experiments output standard. For one, we need to add experiments into the semantic vernacular in addition to metrics, dimensions and attributes. Then, we need to absorb the idea of treatment groups, which we can by making them another dimensional attribute. Each experiment then needs to be mapped to a set of desired metrics and attributes, both target and secondary in nature. But, to perform this mapping, we need to know which entity the experiment is executed on - which brings us to another concept - an experimental entity. With these adds, and glossing over a few nuances, a standard experiment output (sans statistical calculations) can be generated. For a system whether it’s a visualization tool or a data science notebook to interact safely with this standard, the abstraction over a regular cube are the experiment, the entity, the treatment group and metrics/attributes mappings. Now, that’s a new output standard and consequently a strong contract handshake!
2. Segment Contribution: Companies need to understand the main component drivers of a metric. This requires examining the metric, and how various attribute values or segments “build up” towards the metric value. Let’s take 28-day retention rate in a consumer engagement platform - we want to understand how different consumers defined by attributes like age or city or behavioral attributes like their first-day engagement drive this metric. An output calculation here generates the classic metric cube, then calculates each segment’s contribution to the metric, and rank orders the segment. While this is a simple transformation on top of the cube, making this a “segment contribution” standard now establishes a pattern, and makes it available to be generated reliably or composed on.
3. Segment Impact: Companies need to understand why a key metric has changed. This requires analyzing the metric to understand how various attribute values or segments “drive” the metric changes over time. Now, we can compose on a segment contribution output (defined previously) where we take two segment contributions over time windows, and compute how the change in contributions is impacting the change in metric - this now yields a “segment impact” output answering the question: which segments impacted the change in this metric between time windows t1 and t2? This analysis is executed far too frequently in organizations via scrounging through different dashboards that it merits standardization.
Defining output standards and contracts based on business semantics promises two big benefits 1) improved org-wide understanding and collaboration between data and business teams 2) the ability for software to reliably generate analyses that otherwise requires careful manual crafting. Working with defined standards enables organizational velocity. We can run more of these outputs, and with confidence so there is no harsh tradeoff between velocity and quality. This can also be run by users who lack deep understanding of the datasets, the schema, the sql. So, we get velocity, quality, a governed democracy - and consequently, we are getting much more value out of our data.
Establishing standards and contracts does incur a higher upfront cost than the current wild-west approach to data analytics, but any organization seeking to build high-performance, collaborative data and business teams should rather pay this cost than the perpetual cost of back-and-forth broken communications, unreliable and unpredictable hand-crafted outputs.